doi: 10.62486/latia202490
REVISIÓN
Use of artificial intelligence in the detection of coffee rust: An exploratory systematic review
Uso de la inteligencia artificial en la detección de la roya del café: Revisión sistemática exploratoria
Richard Injante1 ![]() *, Karen Chamaya1
*, Karen Chamaya1 ![]() *
*
1Universidad Nacional de San Martín, Facultad de Ingeniería de Sistemas e Informática. Tarapoto, Perú.
Citar como: Injante R, Chamaya K. Use of artificial intelligence in the detection of coffee rust: An exploratory systematic review. LatIA. 2024; 2:90. https://doi.org/10.62486/latia202490
Enviado: 01-02-2024 Revisado: 17-05-2024 Aceptado: 07-09-2024 Publicado: 08-09-2024
Editor: Dr.
Rubén González Vallejo ![]()
Autor para la correspondencia: Richard Injante *
ABSTRACT
Coffee rust, caused by the fungus Hemileia vastatrix, is a fungal disease that affects coffee production and quality, so its early detection is crucial to prevent massive outbreaks and protect production. This article analyzes the most effective factors, the algorithms used, the accuracy of the models, and the challenges in the detection of coffee rust, through an exploratory systematic review of 35 empirical articles obtained from Scopus, IEEE Xplore and SciELO. The review identifies that the most determinant factors for detection include humidity, temperature and the presence of shade. The most commonly used algorithms are Convolutional Neural Networks (CNN), Support Vector Machines (SVM) and Random Forest, highlighting CNN for its ability to process and analyze images with an accuracy of 99,57 %, followed by Artificial Neural Networks (ANN) with 98% and SVM with 96%. However, it is concluded that challenges remain such as the need for high quality labeled datasets, variability in environmental conditions and implementation costs. This study provides a comprehensive overview of recent advances and areas for improvement in coffee rust detection, providing information for researchers, practitioners and decision makers in the agricultural sector.
Keywords: Hemileia Vastatrix; Machine Learning; CNN; SVM; Random Forest.
RESUMEN
La roya del café, causada por el hongo Hemileia vastatrix, es una enfermedad fúngica que afecta la producción y calidad del café, por lo que su detección temprana es crucial para prevenir brotes masivos y proteger la producción. Este artículo analiza los factores más efectivos, los algoritmos empleados, la precisión de los modelos, y los desafíos en la detección de la roya del café, a través de una revisión sistemática exploratoria de 35 artículos empíricos obtenidos de Scopus, IEEE Xplore y SciELO. La revisión identifica que los factores más determinantes para la detección incluyen la humedad, la temperatura y la presencia de sombra. Los algoritmos más utilizados son las Redes Neuronales Convolucionales (CNN), Support Vector Machines (SVM) y Random Forest, destacando las CNN por su capacidad para procesar y analizar imágenes con una precisión del 99,57 %, seguidas por Redes Neuronales Artificiales (ANN) con un 98% y SVM con un 96%. Sin embargo, se concluye que persisten desafíos como la necesidad de conjuntos de datos etiquetados de alta calidad, la variabilidad en las condiciones ambientales y los costos de implementación. Este estudio ofrece una visión integral de los avances recientes y las áreas de mejora en la detección de la roya del café, proporcionando información para investigadores, profesionales y tomadores de decisiones en el sector agrícola.
Palabras clave: Hemileia Vastatrix; Aprendizaje Automático; CNN; SVM; Random Forest.
INTRODUCCIÓN
La roya es una enfermedad fúngica que afecta a las plantas de café. Se manifiesta como manchas de color naranja o marrón en las hojas, ocasionando la baja producción y la calidad del café.(1) Por lo tanto, la detección temprana de la roya es necesaria para prevenir brotes masivos, proteger la cosecha y la calidad del café, y permitir una gestión más eficiente de la enfermedad.(2) En este sentido, la producción mundial de café enfrenta problemas debido a diversas enfermedades que atacan las hojas de las plantas, la calidad y cantidad de la cosecha.(1) Entre estas enfermedades, la roya del café, causada por el hongo Hemileia vastatrix, es uno de los principales factores limitantes y el patógeno más importante para las plantas de café en todo el mundo.(3)
La roya del café es una enfermedad epidémica fúngica que ha afectado a los cafetos globalmente desde la década de 1980, causando defoliaciones masivas y pérdidas de hasta el 80% de la cosecha en algunas regiones.(4) Esta enfermedad provoca pérdidas económicas y sociales (5) al interrumpir las funciones vitales de las plantas y reducir la fotosíntesis, disminuyendo el rendimiento del café (2). Las epidemias de roya en Coffea arábica han provocado crisis socioeconómicas en América Latina desde 2008, y el conocimiento disperso sobre el patosistema de la roya ha dificultado el desarrollo de modelos de previsión.(6)
La roya puede resultar en una pérdida del 50% de hojas y una reducción del 70% en la producción de café,(7) mientras que otras enfermedades también afectan la calidad del grano y los ingresos económicos.(8) La detección temprana es necesaria para prevenir infestaciones que causen destrucción masiva de plantaciones y pérdidas comerciales.(5) Los avances en la detección de la roya del café son evidentes a través de diversas investigaciones. Por ejemplo,(1) destacan la eficacia de las arquitecturas de aprendizaje profundo, como EfficientNet-B0, ResNet-152 y VGG-16, logrando una alta precisión del 97,31 %.
Esta precisión es fundamental para abordar la enfermedad de manera oportuna, como señalan,(3) quienes exploraron el uso de imágenes de drones para la detección temprana de la roya del café, obteniendo una precisión del 80%. Estos resultados revelan cómo la tecnología puede contribuir a la identificación rápida de la enfermedad, permitiendo una respuesta efectiva por parte de los agricultores. Además,(9) presentaron un sistema híbrido que combina árboles de decisión y procesamiento de imágenes para identificar enfermedades del cafeto, alcanzando una precisión del 94,5 %, cuyo enfoque destaca la importancia de la integración de diferentes tecnologías para mejorar la detección de enfermedades en los cultivos. En (5), llevaron esta integración un paso más allá al combinar teledetección, redes de sensores inalámbricos y aprendizaje profundo para diagnosticar la roya del café. En su estudio demostraron la viabilidad de usar tecnologías integradas para lograr una precisión del 77,5 % en la detección de la enfermedad, indicando un avance en la capacidad de diagnosticar con precisión el desarrollo de la roya del café, ofreciendo una solución evaluativa para los agricultores. Por otra parte,(7) complementan estos hallazgos al explorar el uso de imágenes de vehículos aéreos no tripulados (UAV) y técnicas de aprendizaje automático para detectar la roya del café, con una precisión del 91,5 % para las clases de infestación temprana y avanzada, resultados que demuestran ser una herramienta para la detección eficiente de la enfermedad en las plantaciones de café.
El objetivo de este artículo de revisión sistemática es analizar los aspectos relacionados con la detección de la roya del café, centrándose en la identificación de los factores más efectivos, los algoritmos más utilizados, la precisión alcanzada por los modelos implementados, así como los desafíos y limitaciones inherentes a estas técnicas. Se pretende abordar cada uno de estos aspectos de manera integral y crítica, con el fin de ofrecer una visión completa y actualizada de la situación en este campo de investigación. A través de la recopilación y análisis de evidencia empírica, se busca proporcionar una mejor comprensión de los avances recientes, las tendencias emergentes y las áreas de mejora en la detección de la roya del café mediante el uso de técnicas de aprendizaje automático y otras metodologías afines. Por lo tanto, este estudio aspira a ser una referencia para investigadores, profesionales y tomadores de decisiones interesados en este importante problema agrícola.
MÉTODO
Se llevó a cabo una revisión sistemática exploratoria con el objetivo principal de analizar y sintetizar la literatura académica existente en un área específica del conocimiento.(10) Este tipo de revisión proporciona una comprensión exhaustiva y rigurosa del estado del arte al identificar, evaluar y sintetizar críticamente los resultados de estudios anteriores.(11) De esta manera, resulta una herramienta esencial en la investigación científica, permitiendo identificar vacíos en el conocimiento y establecer una base sólida para decisiones informadas.
El método de revisión adoptó las fases propuestas por:(12) planificación, realización de la revisión y redacción del informe. Este enfoque busca definir las preguntas de investigación, establecer los términos clave y sus sinónimos para la búsqueda, seleccionar las bases de datos y determinar los criterios de inclusión y exclusión. Una vez localizado el material de calidad, se examina minuciosamente para extraer información relevante y, finalmente, se reportan los hallazgos.(13) A continuación, se describen las fases llevadas a cabo en la presente revisión:
Preguntas de investigación
Para responder el objetivo propuesto, se trazaron las siguientes preguntas de investigación:
P1: ¿Qué factores son más efectivos para la detección de la roya del café?
P2: ¿Cuáles son los algoritmos más comúnmente utilizados para la detección de la roya del café?
P3: ¿Cuál es la precisión de los modelos en la identificación de la roya del café?
P4: ¿Cuáles son los desafíos y limitaciones actuales en el uso de técnicas de aprendizaje automático para la detección de la roya del café?
Estrategia de búsqueda
Se utilizaron las palabras clave “Coffee rust” y “Hemileia vastatrix”. Para combinar estos términos de búsqueda y formar una cadena de búsqueda integral, se empleó el operador booleano OR. Así, la cadena de búsqueda definida fue: “Coffee rust” OR “Hemileia vastatrix”. Se seleccionaron tres bases de datos: Scopus, IEEE Xplore y SciELO, debido a su amplia cobertura tanto internacional como regional, la facilidad para aplicar filtros de búsqueda avanzada y la garantía de calidad académica en las contribuciones.
El proceso de selección de artículos se inició aplicando la cadena de búsqueda utilizando las herramientas de búsqueda avanzada en cada base de datos, enfocándose en el campo del título, resumen y palabras clave (primera clasificación). Luego, se aplicaron filtros considerando algunos de los criterios de inclusión y exclusión manuales, tales como tipo de documento, cobertura temporal e idioma (segunda clasificación). Posteriormente, los metadatos fueron importados y organizados en Excel, donde se eliminaron los duplicados tomando como referencia la base de datos de Scopus (tercera clasificación). Además, mediante la lectura de títulos y resúmenes, se filtraron los artículos centrados en la detección de la roya del café utilizando inteligencia artificial (cuarta clasificación). Finalmente, se realizó la descarga de artículos según su disponibilidad (quinta clasificación). La tabla 1 presenta la cantidad de artículos obtenidos en cada etapa de clasificación.
|
Tabla 1. Cantidad de artículos según clasificación |
|||||
|
Base de datos |
Fase 1 |
Fase 2 |
Fase 3 |
Fase 4 |
Fase 5 |
|
Scopus |
540 |
215 |
215 |
30 |
28 |
|
IEEE |
27 |
25 |
22 |
18 |
7 |
|
Scielo |
84 |
32 |
16 |
1 |
0 |
|
Total |
35 |
||||
Criterios de inclusión y exclusión
Definir criterios de inclusión y exclusión es crucial para asegurar la objetividad y la reproducibilidad de la revisión. Estos criterios son esenciales para garantizar que los artículos seleccionados sean pertinentes para las preguntas de investigación y cumplan con los estándares de calidad establecidos.(12) Por ello, se establecieron los siguientes criterios de inclusión:
· Solo artículos originales
· Publicados entre el año 2017 y 2024
· Idioma español e inglés
· Enfocados en la detección de la roya del café.
En cuanto a los criterios de exclusión se establecieron los siguientes:
· Artículos de revisión, conferencias u otros tipos de fuentes secundarias
· Publicaciones duplicadas
Extracción de datos
Entre la información recopilada de los 35 artículos seleccionados, se incluyen los siguientes aspectos: código, título, autor, año y base de datos. La base de datos de los artículos analizados puede ser solicitado al autor de correspondencia.
RESULTADOS Y DISCUSIÓN
Tras finalizar la selección de los artículos pertinentes y llevar a cabo una revisión minuciosa de cada uno, se procedió a responder las preguntas de investigación planteadas:
P1: ¿Qué factores son más efectivos para la detección de la roya del café?
La pregunta busca identificar y evaluar los diferentes elementos o variables que influyen en la capacidad de detectar la roya del café de manera eficaz. Así como investigar cuáles son los métodos, tecnologías, indicadores o condiciones que contribuyen a la identificación precisa y oportuna de esta enfermedad en las plantas de café.
|
Tabla 2. Factores para la detección de la roya del café |
||
|
Factores |
Artículos |
Cantidad |
|
Humedad |
(14), (15), (16), (17), (18), (19), (20), (21), (22), (23), (24), (25), (26), (27), (28), (29) |
16 |
|
Temperatura |
(14), (15), (30), (16), (17), (19), (20), (23), (24), (25), (26), (27), (28), (29) |
15 |
|
Lluvia |
(30), (19), (20), (21), (23), (31), (32), (26), (29) |
9 |
|
Monitoreo de la incidencia |
(30), (17), (33), (34), (35), (36), (37), (38), (27), (39), (28) |
11 |
|
Densidad de la vegetación |
(15), (3), (33), (18), (40), (20), (21), (22), (41), (27) |
10 |
|
Precipitación |
(14), (16), (24) |
3 |
|
Presencia de sombra |
(14), (15), (17), (33), (42), (34), (43), (44), (21), (22), (32), (27), (28) |
13 |
La tabla 2 indica que la humedad y la temperatura son los factores más frecuentemente mencionados en la literatura, con 16 y 15 artículos respectivamente. Esto sugiere que estos dos factores son ampliamente usados para la detección de la roya del café. La humedad y la temperatura influyen directamente en el desarrollo y la propagación del hongo Hemileia vastatrix, lo que justifica su alta frecuencia de mención. La presencia de sombra también es un factor significativo, mencionado en 13 artículos. La sombra puede afectar el clima de las plantaciones, influenciando la humedad y temperatura locales, lo que a su vez impacta en la incidencia de la roya. El monitoreo de la incidencia, que implica la observación y registro sistemático de la enfermedad en el campo, es mencionado en 11 artículos. Esto destaca la importancia de las prácticas de vigilancia activa para la detección temprana y el manejo de la enfermedad. Otros factores como la lluvia, la densidad de la vegetación y la precipitación, aunque menos mencionados, también juegan roles importantes. La lluvia y la precipitación pueden influir en la humedad ambiental, mientras que la densidad de la vegetación puede afectar la circulación del aire y la distribución de la humedad. Este análisis sugiere que, para la detección y manejo efectivo de la roya del café, se deben priorizar estrategias que monitoreen y modifiquen las condiciones de humedad y temperatura en los cultivos, además de considerar la influencia de la sombra y la densidad de la vegetación.
P2: ¿Cuáles son los algoritmos más comúnmente utilizados para la detección de la roya del café?
Esta pregunta busca identificar y describir los métodos computacionales y técnicas de inteligencia artificial que se emplean con mayor frecuencia para detectar la presencia de la roya del café. La intención es entender qué tipos de algoritmos son preferidos y aplicados en investigaciones y aplicaciones prácticas para diagnosticar esta enfermedad.
|
Tabla 3. Algoritmos utilizados para la detección de la roya del café |
||
|
Algoritmos |
Artículos |
Cantidad |
|
Support Vector Machines (SVM) |
(3), (17), (42), (40), (19), (24), (41) |
7 |
|
Algoritmos de emparejamiento |
(14), (16) |
2 |
|
Random Forest |
(15), (35), (37), (23), (32) |
5 |
|
Redes Neuronales Convolucionales (CNN) |
(33), (42), (34), (36), (18), (43), (44), (38), (31), (25), (26), (27), (39), (45), (29) |
14 |
|
K-means clustering |
(30) |
1 |
|
MobileNetV3 |
(46) |
1 |
|
Redes Neuronales Artificiales |
(17), (37), (22), (24) |
4 |
|
Naive Bayes |
(17), (20), (21), (24) |
4 |
La tabla 3 muestra una variedad de algoritmos utilizados para la detección de la roya del café y su frecuencia de aparición en la literatura científica. Redes Neuronales Convolucionales (CNN) son el algoritmo más frecuentemente citado, apareciendo en 14 artículos. Esta alta frecuencia indica que las CNN son ampliamente reconocidas por su eficacia en la detección de la roya del café. Las CNN son particularmente efectivas en el procesamiento y análisis de imágenes, lo que las hace ideales para identificar patrones visuales asociados con la enfermedad en las hojas del café.
Support Vector Machines (SVM) son el segundo algoritmo más citado, mencionado en 7 artículos. Las SVM son populares debido a su capacidad para manejar datos de alta dimensión y su eficacia en la clasificación binaria, que es útil para distinguir entre hojas sanas y afectadas por la roya.
Random Forest es mencionado en 5 artículos, lo que indica una preferencia moderada por este algoritmo. Random Forest es apreciado por su robustez y precisión, así como por su capacidad para manejar grandes conjuntos de datos y variables interrelacionadas, lo que es común en el análisis de datos agrícolas.
Redes Neuronales Artificiales y Naive Bayes son mencionados en 4 artículos cada uno. Las Redes Neuronales Artificiales (ANN) son valiosas por su capacidad de aprender y modelar relaciones no lineales complejas. Por otro lado, Naive Bayes es un algoritmo simple y eficiente, especialmente útil en casos donde se requiere una clasificación rápida con un modelo probabilístico. Algoritmos de emparejamiento aparecen en 2 artículos, indicando un uso limitado pero específico, posiblemente en técnicas de comparación directa de características o patrones de imagen.
K-means clustering y MobileNetV3 son mencionados en 1 artículo cada uno. K-means clustering se utiliza para la segmentación y agrupamiento de datos, pero su baja frecuencia de mención sugiere que no es una técnica principal para la detección de la roya del café. MobileNetV3, una arquitectura de red neuronal optimizada para dispositivos móviles, también tiene una mención limitada, lo que puede indicar su aplicación emergente en escenarios específicos que requieren modelos ligeros y eficientes.
Los algoritmos más comúnmente utilizados para la detección de la roya del café, según la literatura científica, son las Redes Neuronales Convolucionales (CNN), seguidas por Support Vector Machines (SVM) y Random Forest. Estas técnicas destacan por su capacidad para procesar y analizar grandes volúmenes de datos, especialmente imágenes, y por su alta precisión en la clasificación. Las Redes Neuronales Artificiales y Naive Bayes también son utilizados, aunque en menor medida, por su capacidad de modelar relaciones complejas y proporcionar resultados rápidos. Otros algoritmos como los de emparejamiento, K-means clustering y MobileNetV3 son mencionados con menos frecuencia, lo que sugiere su uso en aplicaciones más especializadas o emergentes.
P3: ¿Cuál es la precisión de los modelos en la identificación de la roya del café?
Esta interrogante se centra en comprender la exactitud y fiabilidad de los modelos y métodos utilizados para detectar la presencia de la roya del café. La precisión se refiere a la capacidad de un modelo para clasificar correctamente las muestras. Por lo tanto, esta pregunta busca indagar sobre qué tan confiables son los modelos en la identificación precisa de la roya del café, lo que es esencial para la toma de decisiones efectivas en la agricultura y la gestión de cultivos.
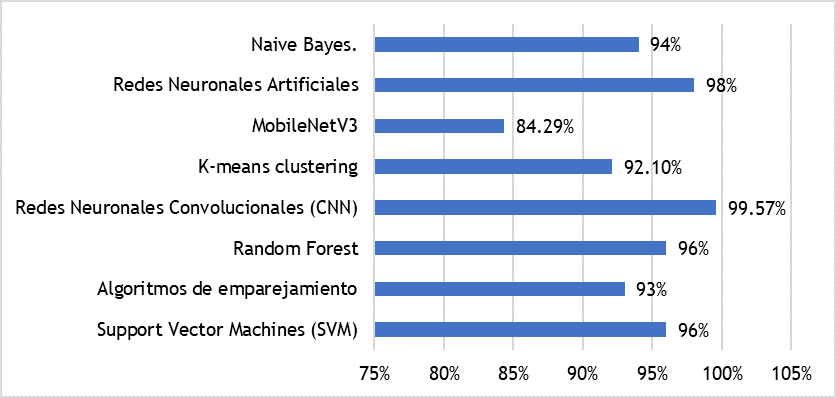
Figura 1. Precisión de los modelos en la identificación de la roya del café
En la figura 1, se evaluaron varios modelos de inteligencia artificial para la detección de la roya del café, destacándose diferencias en sus niveles de precisión. Las Redes Neuronales Convolucionales (CNN) emergieron como el modelo más preciso con una notable tasa de acierto del 99,57 %. Esta alta precisión se debe a su capacidad para extraer y procesar características jerárquicas de las imágenes, haciéndolas extremadamente efectivas para tareas de clasificación de imágenes complejas.
Las Redes Neuronales Artificiales (ANN) y los modelos de Support Vector Machines (SVM) y Random Forest también demostraron una alta precisión, con tasas de 98% y 96% respectivamente. Estos modelos son muy eficaces en la identificación de la roya del café, aprovechando sus capacidades para modelar relaciones no lineales y manejar grandes conjuntos de datos sin sobreajuste. Otros modelos como Naive Bayes y los Algoritmos de Emparejamiento mostraron precisiones del 94% y 93%, respectivamente. Aunque algo inferiores en comparación con los modelos mencionados anteriormente, aún presentan una fiabilidad considerable en la detección de la roya del café, beneficiándose de su simplicidad y eficiencia en el cálculo probabilístico.
Por otro lado, el modelo MobileNetV3 mostró una precisión más baja del 84,29 %. Esta menor exactitud podría deberse a su diseño optimizado para dispositivos móviles, lo cual implica una reducción en la capacidad de procesamiento a cambio de eficiencia computacional.
P4: ¿Cuáles son los desafíos y limitaciones actuales en el uso de técnicas de aprendizaje automático para la detección de la roya del café?
Esta pregunta explora los obstáculos o restricciones que enfrentan las técnicas de aprendizaje automático en su aplicación para detectar la roya del café. Busca comprender las dificultades prácticas, técnicas o conceptuales que pueden afectar la efectividad de estas técnicas en la identificación de la enfermedad.
|
Tabla 4. Desafíos y limitaciones actuales para la detección de la roya del café |
||
|
Desafíos Y Limitaciones |
Artículos |
Cantidad |
|
Necesidad de conjuntos de datos etiquetados de alta calidad |
(14), (15), (30), (16), (17), (33), (34), (36), (43), (40), (19), (44), (37), (23), (24), (31), (27), (29) |
18 |
|
Variabilidad en las condiciones ambientales |
(14), (3), (17), (42), (35), (22), (32), (25), (26), (39) |
10 |
|
Transferencia de modelos entrenados a diferentes ubicaciones geográficas con diferentes variedades de café |
(21), (32), (28), (46) |
4 |
|
Costos |
(3), (17), (33), (42), (20), (25), (39), (46) |
8 |
|
Implementación en entornos |
(15), (23), (41) |
3 |
|
Interpretación de los resultados |
(15), (30), (16), (17), (42), (40), (44), (20), (37), (38), (24) |
11 |
|
Necesidad de equipos y tecnologías apropiadas. |
(18), (19), (22), (31), (29) |
5 |
La tabla 4 destaca que la necesidad de conjuntos de datos etiquetados de alta calidad es el desafío más frecuentemente citado, apareciendo en 18 artículos. Esto sugiere que uno de los mayores obstáculos en la implementación efectiva de técnicas de aprendizaje automático para la detección de la roya del café es la disponibilidad y calidad de los datos. Conjuntos de datos insuficientes o mal etiquetados pueden afectar la precisión y confiabilidad de los modelos entrenados. Variabilidad en las condiciones ambientales, mencionada en 10 artículos, es otro desafío importante. Las condiciones climáticas y ambientales pueden variar entre diferentes regiones y estaciones, lo que puede afectar la precisión de los modelos si no se consideran estas variaciones en los datos de entrenamiento y validación.
Interpretación de los resultados, con 11 menciones, es también otro desafío. Los modelos de aprendizaje automático, especialmente los más complejos como las redes neuronales, pueden ser difíciles de interpretar, lo que complica la comprensión de las decisiones del modelo y la confianza en los resultados obtenidos. Asimismo, los costos, mencionado en 8 artículos, indica que la implementación de estas técnicas puede ser costosa debido a la necesidad de recursos computacionales, adquisición de datos y mantenimiento de infraestructura tecnológica.
Transferencia de modelos entrenados a diferentes ubicaciones geográficas con diferentes variedades de café, con 4 menciones, refleja la dificultad de aplicar modelos desarrollados en una región específica a otras regiones con diferentes condiciones y variedades de café. Esto limita la generalización y aplicabilidad de los modelos entrenados. Necesidad de equipos y tecnologías apropiadas, mencionada en 5 artículos, destaca la necesidad de hardware y software avanzados para ejecutar los modelos de aprendizaje automático, lo que puede no estar disponible en todas las áreas productoras de café.
Implementación en entornos, con 3 menciones, se refiere a los desafíos prácticos de integrar estas tecnologías en los sistemas de gestión agrícola existentes, lo cual requiere cambios en las prácticas y procesos actuales. Los desafíos y limitaciones actuales en el uso de técnicas de aprendizaje automático para la detección de la roya del café son variados. El más crítico es la necesidad de conjuntos de datos etiquetados de alta calidad, que es esencial para entrenar modelos precisos y confiables. La variabilidad en las condiciones ambientales y la interpretación de los resultados son también desafíos importantes que afectan la precisión y la confianza en los modelos.
CONCLUSIONES
En esta revisión destacan la importancia de la detección temprana de la roya del café para mitigar sus efectos en la producción y calidad del café. La revisión de la literatura revela que los factores ambientales como la humedad y la temperatura son determinantes en la proliferación de la enfermedad, y su monitoreo puede mejorar las estrategias de manejo. La integración de tecnologías avanzadas, como el uso de drones e imágenes satelitales, ha mostrado una capacidad para detectar la roya del café con altos niveles de precisión, contribuyendo a la reducción de pérdidas económicas en las áreas productoras de café.
Los algoritmos de aprendizaje automático, particularmente las CNN, han demostrado ser los más eficaces en la detección de la roya del café, alcanzando precisiones superiores al 99%. Otros modelos como Support Vector Machines (SVM) y Random Forest también ofrecen buenos resultados, aunque con menores niveles de precisión en comparación con las CNN. Sin embargo, la implementación de estos modelos enfrenta desafíos, incluyendo la necesidad de conjuntos de datos etiquetados de alta calidad, la variabilidad en las condiciones ambientales y la interpretación de los resultados. Estos obstáculos evidencian la necesidad de un enfoque multidisciplinario que combine la experiencia agrícola con avances tecnológicos y métodos computacionales robustos.
Para futuras investigaciones, se sugiere ampliar el alcance de las revisiones sistemáticas para incluir tanto estudios previos como más recientes, y explorar otras bases de datos y fuentes de publicación para capturar una gama más amplia de investigaciones sobre la detección de la roya del café mediante inteligencia artificial.
REFERENCIAS BIBLIOGRÁFICAS
1. Novtahaning D, Shah HA, Kang JM. Deep Learning Ensemble-Based Automated and High-Performing Recognition of Coffee Leaf Disease. Agriculture [Internet]. 2022;12(11):1909.
2. Esgario JGM, de Castro PBC, Tassis LM, Krohling RA. An app to assist farmers in the identification of diseases and pests of coffee leaves using deep learning. Inf Process Agric [Internet]. 2022;9(1):38–47.
3. Soares A da S, Vieira BS, Bezerra TA, Martins GD, Siquieroli ACS. Early Detection of Coffee Leaf Rust Caused by Hemileia vastatrix Using Multispectral Images. Agronomy [Internet]. 2022;12(12):2911.
4. Velásquez D, Sánchez A, Sarmiento S, Velásquez C, Toro M, Montoya E, et al. A Cyber-Physical Data Collection System Integrating Remote Sensing and Wireless Sensor Networks for Coffee Leaf Rust Diagnosis. Sensors [Internet]. 2021;21(16):5474.
5. Velásquez D, Sánchez A, Sarmiento S, Toro M, Maiza M, Sierra B. A Method for Detecting Coffee Leaf Rust through Wireless Sensor Networks, Remote Sensing, and Deep Learning: Case Study of the Caturra Variety in Colombia. Appl Sci [Internet]. 2020;10(2):697.
6. Motisi N, Bommel P, Leclerc G, Robin MH, Aubertot JN, Butron AA, et al. Improved forecasting of coffee leaf rust by qualitative modeling: Design and expert validation of the ExpeRoya model. Agric Syst [Internet]. 2022;197:103352.
7. Marin DB, Ferraz GA e S, Santana LS, Barbosa BDS, Barata RAP, Osco LP, et al. Detecting coffee leaf rust with UAV-based vegetation indices and decision tree machine learning models. Comput Electron Agric [Internet]. 2021;190:106476.
8. Martinez F, Montiel H, Martinez F. A Machine Learning Model for the Diagnosis of Coffee Diseases. Int J Adv Comput Sci Appl [Internet]. 2022;13(4).
9. Debasu Mengistu A, Mengistu SG, Alemayehu DM. An Automatic Coffee Plant Diseases Identification Using Hybrid Approaches of Image Processing and Decision Tree. Indones J Electr Eng Comput Sci [Internet]. 2018;9(3):806.
10. Codina L. Scoping reviews: características, frameworks principales y uso en trabajos académicos. 2021; Available from: https://www.lluiscodina.com/scoping-reviews-guia/
11. Munn Z, Peters MDJ, Stern C, Tufanaru C, McArthur A, Aromataris E. Systematic review or scoping review? Guidance for authors when choosing between a systematic or scoping review approach. BMC Med Res Methodol [Internet]. 2018;18(1):143.
12. Kitchenham B, Charters S. Guidelines for performing Systematic Literature Reviews in Software Engineering. Keele Univ y Univ Durham [Internet]. 2007; Available from: https://legacyfileshare.elsevier.com/promis_misc/525444systematicreviewsguide.pdf
13. Alba JRG, Franco RR, Cerdán MA. Sistemas expertos en agricultura de precisión: revisión sistemática de la literatura. Rev Int Desarro Reg Sustentable [Internet]. 2022;7(1–2):247–64. Available from: http://www.rinderesu.com/index.php/rinderesu/article/view/144
14. Lozada G, Valencia G, Lasso E, Corrales JC. Coffee Rust Detection Based on a Graph Similarity Approach. In 2018. p. 82–96.
15. Dumbá Monteiro de Castro G, Ferreira Vilela E, Luísa Ribeiro de Faria A, Antônio Silva R, Pinto Marques Ferreira W. New vegetation index for monitoring coffee rust using sentinel-2 multispectral imagery. Coffee Sci [Internet]. 2023;18:1–13.
16. Lasso E, Valencia O, Corrales DC, López ID, Figueroa A, Corrales JC. A Cloud-Based Platform for Decision Making Support in Colombian Agriculture: A Study Case in Coffee Rust. In 2018. p. 182–96.
17. Rodríguez JP, Girón EJ, Corrales DC, Corrales JC. A Guideline for Building Large Coffee Rust Samples Applying Machine Learning Methods. In 2018. p. 97–110.
18. Rodriguez-Gallo Y, Escobar-Benitez B, Rodriguez-Lainez J. Robust Coffee Rust Detection Using UAV-Based Aerial RGB Imagery. AgriEngineering [Internet]. 2023 Aug 21;5(3):1415–31.
19. Castro W, Oblitas J, Maicelo J, Avila-George H. Evaluation of Expert Systems Techniques for Classifying Different Stages of Coffee Rust Infection in Hyperspectral Images. Int J Comput Intell Syst [Internet]. 2018;11(1):86.
20. Huatangari LQ, Ocaña Zúñiga CL, Huaccha Castillo AE, Acosta Jacinto RE, Milla Pino ME, Julcapoma MR, et al. Detection of Rust Emergence in Coffee Plantations using Data Mining: A Systematic Review. Online J Biol Sci [Internet]. 2022;22(2):157–64.
21. Corrales DC, Lasso E, Casas AF, Ledezma A, Corrales JC. Estimation of coffee rust infection and growth through two-level classifier ensembles based on expert knowledge. Int J Bus Intell Data Min [Internet]. 2018;13(4):369.
22. Beasley EM, Aristizábal N, Bueno EM, White ER. Spatially explicit models predict coffee rust spread in fragmented landscapes. Landsc Ecol. 2022;37(8):2165–78.
23. Calderón CER, Velandia JB, Ayala SCV. Supervised Model for the Detection of Coffee Leaf Diseases by Image Analysis. Rev Int Sist Intel y Apl en Ing [Internet]. 2023;11(3):405–11.
24. Buitrón EJG, Corrales DC, Avelino J, Iglesias JA, Corrales JC. Rule-based expert system for detection of coffee rust warnings in colombian crops. Pinto D, Singh V, editors. J Intell Fuzzy Syst [Internet]. 2019;36(5):4765–75.
25. Carvalho HF, Ferrão LFV, Galli G, Nonato JVA, Padilha L, Maluf MP, et al. On the accuracy of threshold genomic prediction models for leaf miner and leaf rust resistance in arabica coffee. Tree Genet Genomes [Internet]. 2023;19(1):11.
26. Marcos AP, Silva Rodovalho NL, Backes AR. Coffee Leaf Rust Detection Using Genetic Algorithm. In: 2019 XV Workshop de Visão Computacional (WVC) [Internet]. IEEE; 2019. p. 16–20.
27. Marcos AP, Silva Rodovalho NL, Backes AR. Coffee Leaf Rust Detection Using Convolutional Neural Network. In: 2019 XV Workshop de Visão Computacional (WVC) [Internet]. IEEE; 2019. p. 38–42.
28. Paulos EB, Woldeyohannis MM. Detection and Classification of Coffee Leaf Disease using Deep Learning. In: 2022 International Conference on Information and Communication Technology for Development for Africa (ICT4DA) [Internet]. IEEE; 2022. p. 1–6.
29. Lasso E, Motisi N, Avelino J, Corrales JC. FramePests: A Comprehensive Framework for Crop Pests Modeling and Forecasting. IEEE Access [Internet]. 2021;9:115579–98.
30. Lasso E, Corrales DC, Avelino J, de Melo Virginio Filho E, Corrales JC. Discovering weather periods and crop properties favorable for coffee rust incidence from feature selection approaches. Comput Electron Agric [Internet]. 2020;176:105640.
31. Hitimana E, Sinayobye OJ, Ufitinema JC, Mukamugema J, Rwibasira P, Murangira T, et al. An Intelligent System-Based Coffee Plant Leaf Disease Recognition Using Deep Learning Techniques on Rwandan Arabica Dataset. Technologies [Internet]. 2023;11(5):116.
32. Wu W, Wang G, Wang H, Gbokie T, He C, Huang X, et al. Development of a loop-mediated isothermal amplification assay for rapid and sensitive detection of Hemileia vastatrix in coffee plantations. Trop Plant Pathol [Internet]. 2024;49(4):515–24.
33. Belan LL, Belan LL, da Matta Rafael A, Gonçalves Gomes CA, Alves FR, Cintra de Jesus Junior W, et al. Standard area diagram with color photographs to estimate the severity of coffee leaf rust in Coffea canephora. Crop Prot [Internet]. 2020;130:105077.
34. Chavarro AF, Renza D, Ballesteros DM. Influence of Hyperparameters in Deep Learning Models for Coffee Rust Detection. Appl Sci [Internet]. 2023;13(7):4565.
35. Caballero EMT, Duke AMR. Implementation of Artificial Neural Networks Using NVIDIA Digits and OpenCV for Coffee Rust Detection. In: 2020 5th International Conference on Control and Robotics Engineering (ICCRE) [Internet]. IEEE; 2020. p. 246–51.
36. Incahuanaco-Quispe F, Hinojosa-Cardenas E, Pilares-Figueroa DA, Beltrán-Castañón CA. CoffeeSE: Interpretable Transfer Learning Method for Estimating the Severity of Coffee Rust. In 2022. p. 340–55.
37. Sousa IC de, Nascimento M, Silva GN, Nascimento ACC, Cruz CD, Silva FF e, et al. Genomic prediction of leaf rust resistance to Arabica coffee using machine learning algorithms. Sci Agric [Internet]. 2021;78(4).
38. S R, R S. Clustering-based Hemileia Vastatrix Disease Prediction in Coffee Leaf using Deep Belief Network. In: 2023 8th International Conference on Communication and Electronics Systems (ICCES) [Internet]. IEEE; 2023. p. 1094–100.
39. Kumar M, Gupta P, Madhav P, Sachin. Disease Detection in Coffee Plants Using Convolutional Neural Network. In: 2020 5th International Conference on Communication and Electronics Systems (ICCES) [Internet]. IEEE; 2020. p. 755–60.
40. Estrada-Peraza E, Alvarez-Huezo E, Girón-Morales G, Rodriguez-Gallo Y. RGB Image-Based Coffee Rust Detection: Application of Vegetation Indices and Algorithm Development. In: 2023 IEEE Central America and Panama Student Conference (CONESCAPAN) [Internet]. IEEE; 2023. p. 23–8.
41. Chemura A, Mutanga O, Sibanda M, Chidoko P. Machine learning prediction of coffee rust severity on leaves using spectroradiometer data. Trop Plant Pathol [Internet]. 2018;43(2):117–27.
42. Gagliardi S, Avelino J, Beilhe LB, Isaac ME. Contribution of shade trees to wind dynamics and pathogen dispersal on the edge of coffee agroforestry systems: A functional traits approach. Crop Prot [Internet]. 2020;130:105071.
43. Cruz-Estrada LG, Luna-Ramírez WA. Early Detection of Rust in Coffee Plantations Through Convolutional Neural Networks. In 2023. p. 894–904.
44. Suparyanto T, Firmansyah E, Wawan Cenggoro T, Sudigyo D, Pardamean B. Detecting Hemileia vastatrix using Vision AI as Supporting to Food Security for Smallholder Coffee Commodities. IOP Conf Ser Earth Environ Sci [Internet]. 2022;998(1):012044.
45. Montalbo FJP, Hernandez AA. An Optimized Classification Model for Coffea Liberica Disease using Deep Convolutional Neural Networks. In: 2020 16th IEEE International Colloquium on Signal Processing & Its Applications (CSPA) [Internet]. IEEE; 2020. p. 213–8.
46. Faisal M, Leu JS, Darmawan JT. Model Selection of Hybrid Feature Fusion for Coffee Leaf Disease Classification. IEEE Access [Internet]. 2023;11:62281–91.
FINANCIACIÓN
Los autores no recibieron financiación para el desarrollo de la presente investigación.
CONFLICTO DE INTERESES
Los autores declaran que no existe conflicto de intereses.
CONTRIBUCIÓN DE AUTORÍA
Conceptualización: Karen Chamaya y Richard Injante.
Curación de datos: Richard Injante.
Análisis formal: Karen Chamaya y Richard Injante.
Investigación: Karen Chamaya y Richard Injante.
Metodología: Richard Injante.
Administración del proyecto: Karen Chamaya y Richard Injante.
Recursos: Richard Injante.
Supervisión: Richard Injante.
Validación: Richard Injante.
Visualización: Karen Chamaya.
Redacción – borrador original: Karen Chamaya y Richard Injante.
Redacción – revisión y edición: Karen Chamaya y Richard Injante.